Steve B wrote:scandien wrote:Hello again

i get some interesting result for machine vs man under tournament conditions. The Reference is the FIDE rating:
Novag Sapphire : 34 games - perf 2087 (2100 on FICS)
Novag Diablo/Scorpio: 19 games - 2185
MEPHISTO ATLANTA : 6 games - perf 2382
MEPHISTO MILANO/POLGAR : 6 games - perf 2237
MEPHISTO BERLIN PRO : 7 GAMES - perf 2300
FIDELITY DESIGNER MACH III : 4 Games - perf 2160
a lot of data are coming from Hombre machina tounament or AEGON results.4
I know that 6 games is not a lot but it may help for a good tuning. And 19 gales or 34 games are enough to get an official rating.
BR
Nicolas
the MIL And Polgar not the same exact program so why listed together?
anyway ...Lets Compare to Sel Ser human list from 2005
Novag Sapphire : 83 games - 2139
Novag Diablo/Scorpio: 140 games - 2126
MEPHISTO ATLANTA : 9 games -2357
MEPHISTO MILANO 14 games -2087
Mephisto POLGAR 5 Mhz 17 games 2076
MEPHISTO BERLIN PRO : 29 GAMES -2217
FIDELITY DESIGNER MACH III : 245 Games - 2107
All Close except for the MILANO/POLGAR rating
Comparative Regards
Steve
Yep that's all interesting. Kaufmann spent a lot of time on R30 in 1994. He was quite impressed with it and rated King 2.5 at around 2530. The 1994 list showed King 2.2 with a Mean 2526. CCN (Eric Hallsworth) at 2521 and PLY (SSDF) at 2530.
Ok so if you take the mean at 2526 for King 2.2 and if you deduct say the GM average difference of 87 or the 60 from the casinos then you would have a rating for King 2.2 of maybe somewhere between 2439 - 2466 ELO. The Active list rating has it at 2367 which is a difference of between 72 - 99 ELO.
Atlanta in the Active List is 2266 which is 101 ELO lower than the Active King 2.2 rating.
Based on your two independent Human Atlanta ratings the average rating over the combined 15 games is 2367.
Therefore you have the following:
1) Kaufmann, CCN & PLY would probably have rated Atlanta at around 2435
2) Deduct 87 and you get 2348
3) Deduct 60 and you get 2375
Mean = 2362
It is all very close really.
So lets assume the 60 deduction becomes a standard for over 2000. Then at near the top of the dedicated List you would have:
King 2.2 at 2466 as a list calibration computer
Atlanta at 2367 as a list calibration computer (your human rating)
At the bottom you could have:
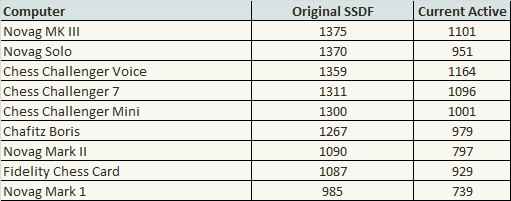
MK I at 985 as a list calibration computer
CC7 (has plenty of games) at 1311 as a list calibration computer
And I think you would soon find that most other computers would quite closely fall into place for a reasonably good comparison against humans.
The problems with todays ratings software like ELO stat or Bayesian is that you can only calibrate one computer. Which means that when you run your list with 300-500 computers, you are very quickly so far away from human ratings that it becomes impossible to compare accurately across the whole list. Think about it you are expecting good human comparison across 500 computers based on 1 calibration. It just doesn't work today.
You almost need 1 calibration per say every 50 computer programs to have a good chance of being accurate across the complete list.
So anyway this brings the circle around to why I posted questions to Nicolas originally
Best regards